> ## Documentation Index
> Fetch the complete documentation index at: https://docs.greenflash.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Voice Agents
> Voice-agent analytics that work on any transcript. No audio storage required. Latency, interruptions, silences, call-end, and prosody analyzers, plus a synced audio timeline on every call.
Voice analytics in Greenflash work on the transcript. We never see, store, or process the audio file. Most voice analytics tools want you to ship them recordings; we don't. If a conversation has voice-shaped data like speakers and per-turn timing, voice analytics runs on it automatically.
Audio never touches Greenflash. When your provider supplies a recording URL, we render an audio player that streams directly from your storage. We analyze the transcript and the timing; the audio file stays yours.
## Auto-detection
You don't have to flag a conversation as "voice" or change anything about how you log. Greenflash looks at the transcript shape and per-turn timestamps, and if it looks like a voice call, the voice analyzers run. Already-instrumented conversations pick up voice analytics retroactively, no backfill.
What this means in practice:
* If you already POST to `/v1/messages` with per-turn timing, voice analytics is already running on those calls.
* If you use Vapi, Retell, ElevenLabs, Bland, Synthflow, or Simple.ai, point the provider's webhook at us and the rest is automatic.
* If you're on something custom (LiveKit, Pipecat, OpenAI Realtime, in-house infra), send the transcript and we'll figure it out from there.
Voice detection needs per-turn timing. If every message in a conversation shares the same timestamp, the voice analyzers won't fire, even if the call really did happen over voice.
## Canonical transcript shape
If you're building an adapter, this is the shape to target. Per-turn timing is the only hard requirement; everything else upgrades the analytics you get back.
**Minimum** (auto-detection fires, latency/interruption/silence analyzers run):
```json theme={"theme":{"light":"github-light","dark":"vesper"}}
{
"role": "assistant",
"content": "Hi, this is Aria — how can I help you today?",
"voice": {
"startedAt": 1700000000000,
"durationMs": 2400
}
}
```
`startedAt` is Unix epoch milliseconds. `durationMs` is how long that turn was spoken. Speaker comes from the standard message `role` (`"user"` / `"assistant"`) — you don't need a separate `voice.speaker` for chat-shaped transcripts.
`voice.speaker` only exists for cases where `role` isn't enough: diarization-only data with no agent/user mapping (e.g. `"Speaker 0"`, `"Speaker 1"`), or transcripts logged via `messageType` instead of `role` where you still want to flag the speaker. If you're already sending `role`, leave `speaker` out.
**Recommended** (unlocks the full set of voice analyzers and timeline annotations):
| Field | Why it helps |
| ---------------------------------------- | --------------------------------------------------------------------------------------------------------- |
| `voice.endedAt` | Lets us draw exact turn boundaries when `durationMs` isn't available |
| `voice.responseLatencyMs` | Drives the TTFA/agent-response latency view; we'll derive it from gaps if missing |
| `voice.asrConfidence` | Surfaces low-confidence turns and feeds the ASR latency analyzer |
| `voice.wasInterrupted` / `voice.bargeIn` | Direct signal into the interruption analyzer (we also detect from overlap, but explicit is more accurate) |
| `voice.silenceBeforeMs` | Direct signal into the silence analyzer |
| `voice.prosody` | Enables the prosody analyzer (sentiment, arousal, emotion); skipped if absent |
At the conversation level, send a `voiceCall` object with `durationMs`, `endedReason`, `recordingUrl` (see below), and `latency` aggregates if your platform exposes them. Full field reference is in the [Public API schema](/features/public-api).
## Five voice analyzers
Five analyzers run on every voice conversation:
| Analyzer | What it surfaces |
| ----------------- | --------------------------------------------------------------------------------------------------------- |
| **Latency** | Per-turn Time-To-First-Audio (TTFA), ASR, LLM, and TTS outliers; flags regressions when you change models |
| **Interruptions** | Barge-in clusters and overlapping speech that signal user frustration |
| **Silences** | Long gaps where the agent stalled or the user dropped off mid-call |
| **Call-end** | Classifies how the call ended (completed, abandoned, escalated, failed) |
| **Prosody** | Sentiment shifts, vocal arousal, and emotion swings across the call |
These are deterministic by design: same transcript in, same result out. We picked it that way so you can compare week-over-week numbers without worrying about LLM drift muddying the comparison. The only analyzer that calls an LLM is call-end, and only as a tiebreaker on cases the rules can't decide.
## Conversation pathologies (voice + text)
Three pathology detectors fire on every conversation, voice or text:
* **Clarification loops:** the agent re-asks the same clarifying question across turns.
* **Repeated information:** the agent re-states context the user already gave.
* **Agent monologue:** long stretches of agent speech with no user input.
These exist because they're real failure modes we kept seeing in conversation reviews. They show up everywhere, but voice transcripts make them painfully obvious because the conversational shape is so visible.
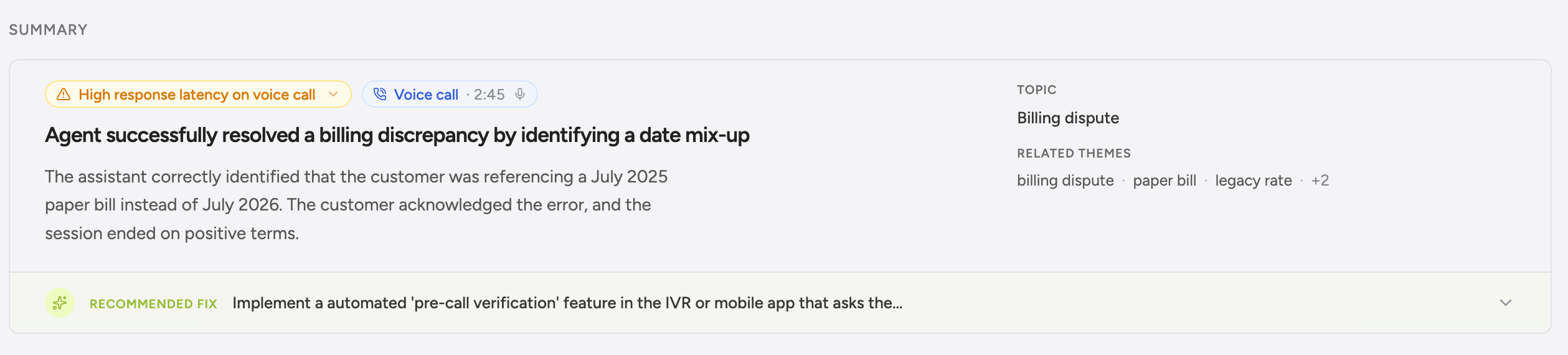
## Voice Call section on conversation detail
Open any voice conversation and the page renders a Voice Call section that's auto-hidden for text. Two pieces share the surface, and it's worth keeping them straight:
* **Call flow timeline (synthesized from the transcript).** Per-turn bars colored by speaker, sized by duration, and marked with interruption and silence flags. Latency overlays (TTFA, ASR, LLM, TTS) sit on each turn. Greenflash draws this view from the per-turn timing on your messages — there's no audio waveform involved, and it renders whether or not a recording exists.
* **Audio player (the real recording).** When `voiceCall.recordingUrl` is set, an HTML `